現在、静的シーンにおける視覚SLAMは高い性能とロバスト性を持っている。
自動運転、拡張現実感、仮想現実感などの様々なシナリオにおいて、動的な周囲の環境を理解する必要があるため、動的な3Dオブジェクト追跡がビジュアルSLAMの重要な機能になっている。
しかし、単眼画像のみでダイナミックSLAMを行うことは、動的特徴の関連付けとその位置推定が困難であるため、依然として困難な問題である。
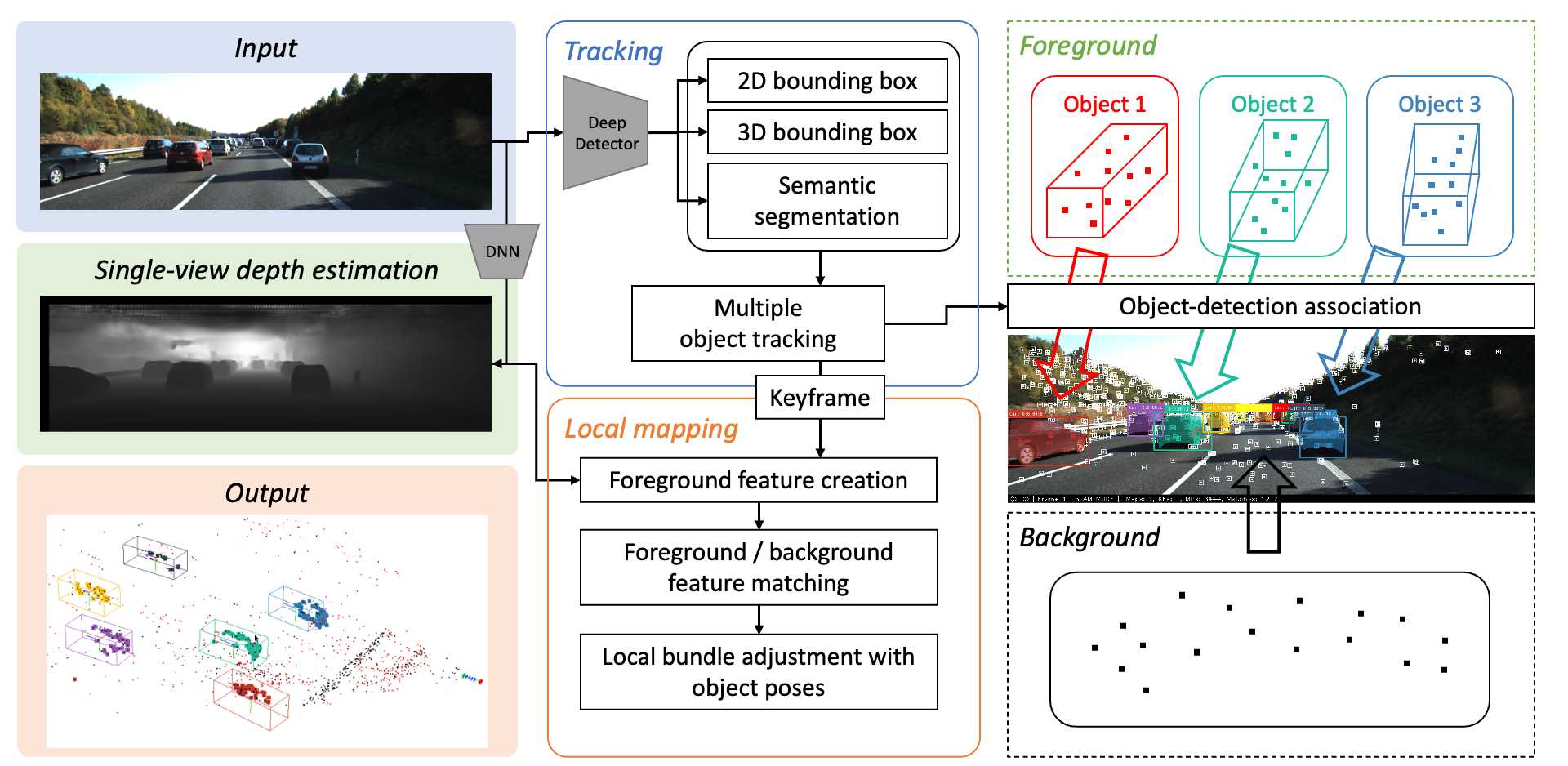
そこで本研究では、単眼構成で動的物体の姿勢とバウンディングボックスの両方を追跡する動的ビジュアルSLAMシステム、MOTSLAMを提案する。
MOTSLAMはまず、2Dおよび3Dのバウンディングボックス検出を伴うマルチオブジェクト追跡(MOT)を行い、初期の3Dオブジェクトを作成する。
次に、ダイナミックな特徴の深さを取得するため、ニューラルネットワークベースの単眼深度推定が適用される。
最後に、カメラポーズ、オブジェクトポーズ、静的および動的なマップポイントを、新しいバンドル調整法を用いて共同で最適化する。
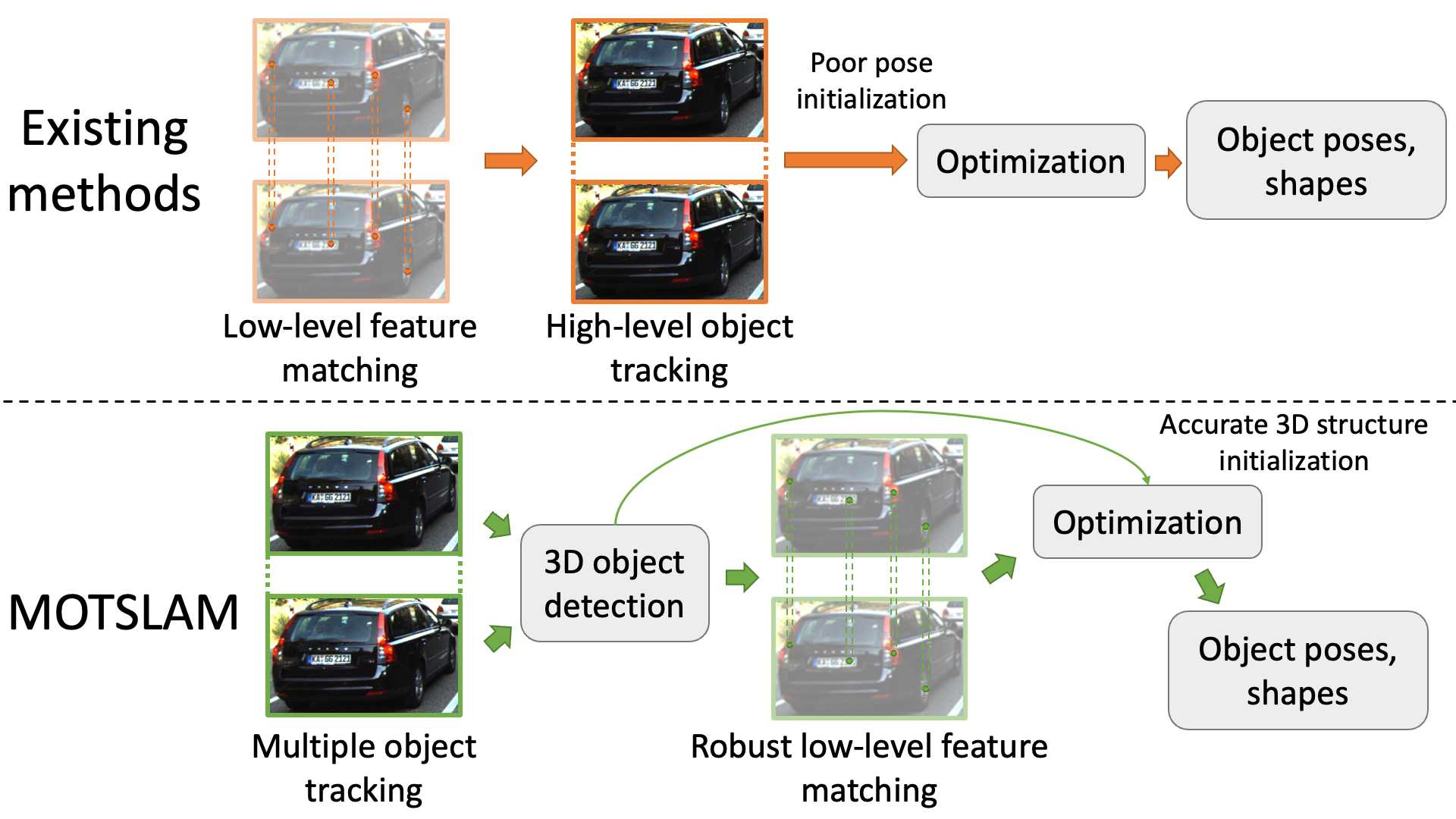
既存の研究では、高レベルのオブジェクトの関連付けのため、低レベルの特徴の対応付けが必要である。
しかし、実世界では物体は様々な動きをするため、線形運動モデルが不適用な場合は少なくない。
さらに重要な問題として、事前準備なしに疎な特徴量から3次元再構成を行うと、実物と合わない形状が生成されることが多いである。
上記の問題を解決するため、動的特徴量追跡の前に複数物体追跡を導入することにより、本研究の主な貢献になっている。
ここでのMOTは、低レベルと高レベルの関連付けの順序を逆にする。
各フレームにおいて、カメラ自己位置推定の前にMOTによってオブジェクトトラッキングを行う。
そのため、このフレームの残りの部分は、現在の全ての物体の比較的正確な姿勢と形状がわかる。
これにより、動的特徴量の追跡と最適化に先立ち、より精度高いモーションを提供できる。
同時に、三角測量のための2Dベースの特徴マッチングの欠点を避けるため、深度推定を導入している。
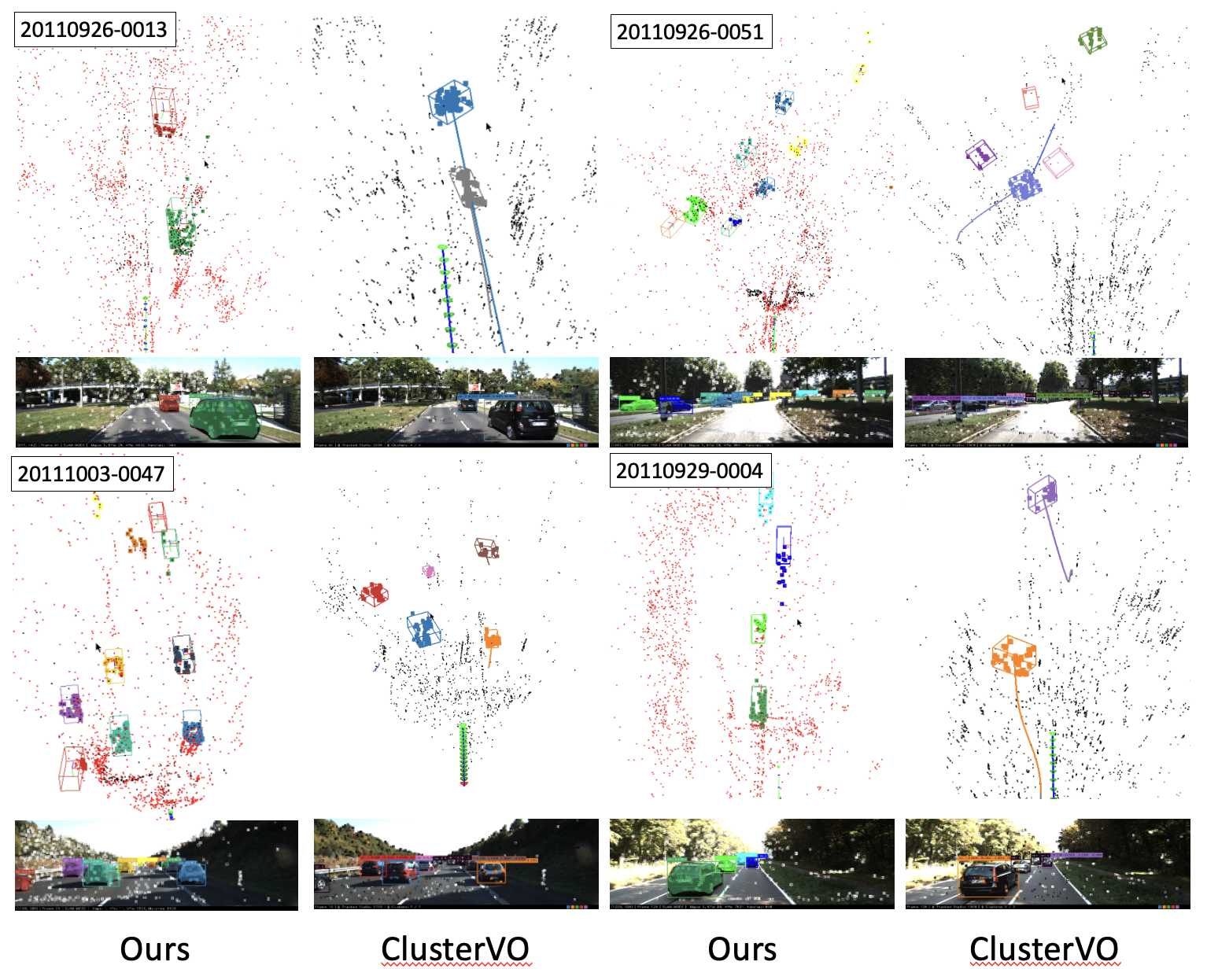
本研究は、KITTIデータセットを用いてシステムを評価する。
オブジェクトトラッキングの性能に焦点を当てる。
本システムは、バウンディングボックスの精度において、既存の最先端手法を大きく上回っている。
また、より多くのオブジェクトを追跡し、より規則的な車両形状を生成することを確認できた。
Publications
|