| 深層学習によるタイプ識別によるコミュニケーションロボットのジェスチャ生成 |
近年、アバターやソーシャルロボットといった人間の代わりを果たす媒体が急速に発展している。これらは人間とのコミュニケーションを主眼に置いて開発されたものであり、これらをより人間らしく見せるための改善点の一つとしてより自然で適切なジェスチャーを行わせることが挙げられる。近年のジェスチャー生成システムは文章や音声等の情報からEnd-to-endでDNNを学習してジェスチャーを生成する傾向にある。しかし、多くの先行研究では音声やテキストの特徴量を単純に結合してネットワークに入力しているため、各モダリティに合ったジェスチャーを生成することは難しい。そこで我々は、テキストを入力としてジェスチャーの種類を明示的に考慮しながらジェスチャーを生成する手法を提案する。
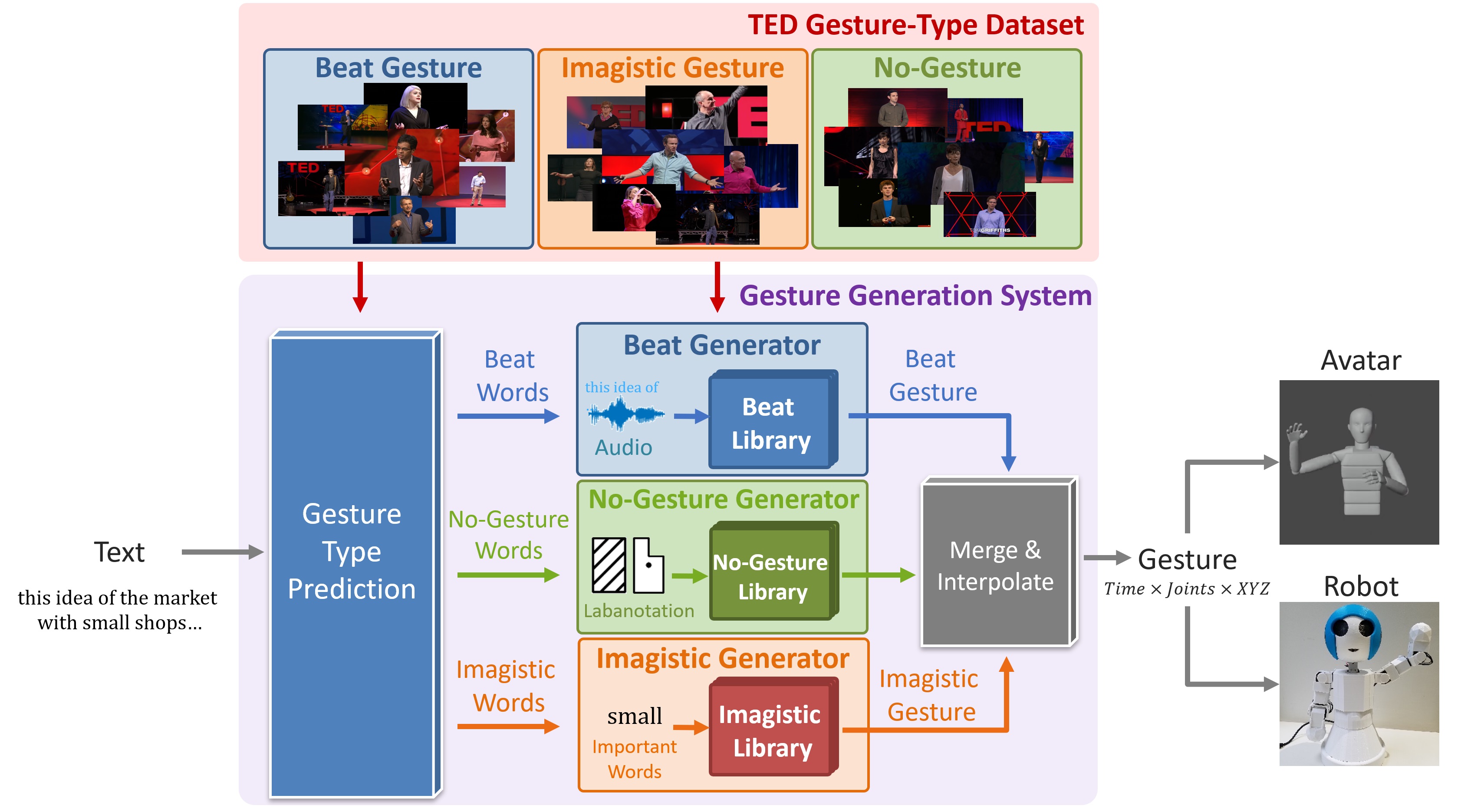
我々が扱うTEDの動画の各時間は大きく以下の3種類の動き(ジェスチャータイプ)に区分できる。
テキストからジェスチャータイプを予測する際やジェスチャーライブラリを構築する際にはジェスチャータイプの注釈が付いたジェスチャーデータベースが必要である。我々はクラウドソーシングサービスを活用してTEDの動画をジェスチャーごとに分割し、ジェスチャータイプをアノテーションすることで、TED Gesture Type Datasetとして新たなデータベースを収集した。 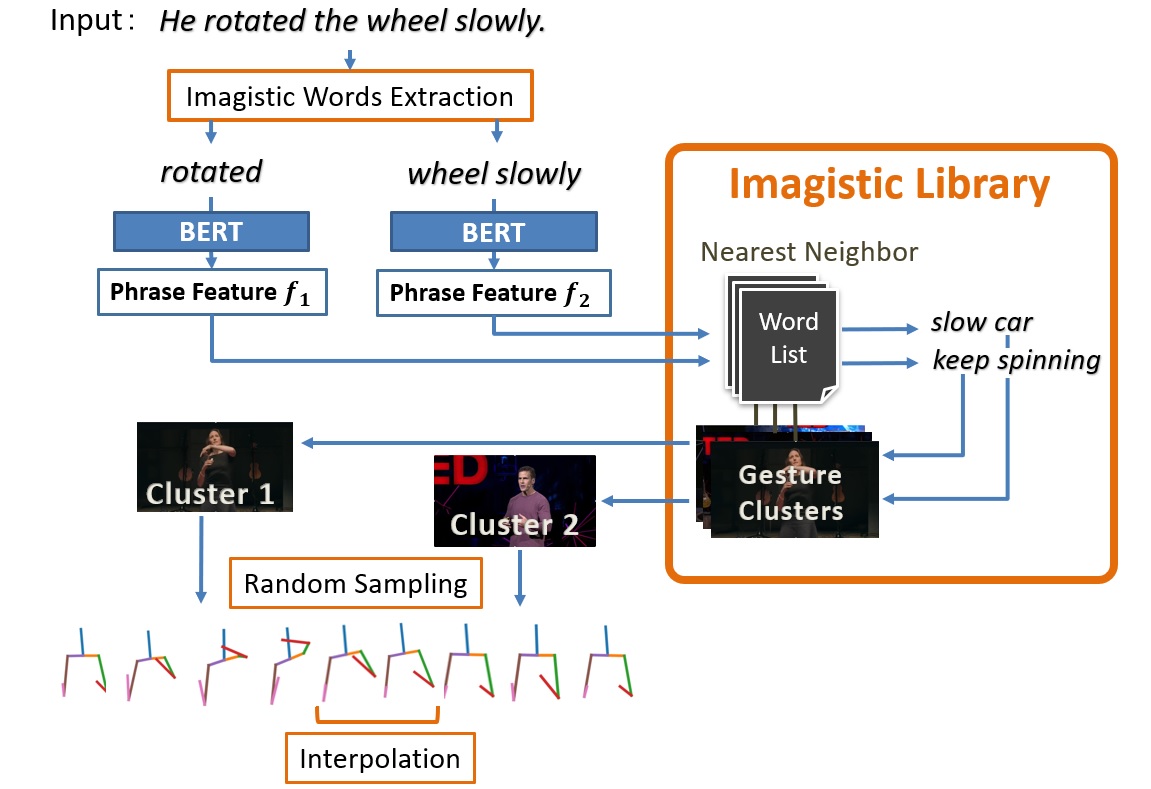
単語列から実際にジェスチャーを生成するプロセスとして、例えばImagistic Generatorでは、まず、入力単語列の中からImagisticジェスチャーが現れそうな単語を深層学習により選出する。その後、各単語をBERTを用いてエンコードし、ジェスチャーライブラリに入力することで、ライブラリから最も意味の近い単語に対応するジェスチャークラスタが検索される。検索されたジェスチャークラスタからランダムにジェスチャーが選ばれ、出力される。以下の画像が実際に生成されたジェスチャーの例で、それぞれオリジナルのジェスチャー(GT)、提案手法により生成されたジェスチャー(Ours)、とランダムにデータベースから参照されたジェスチャー(Random)、先行研究の手法により生成されたジェスチャー(Yoon, Kucherenko)である。 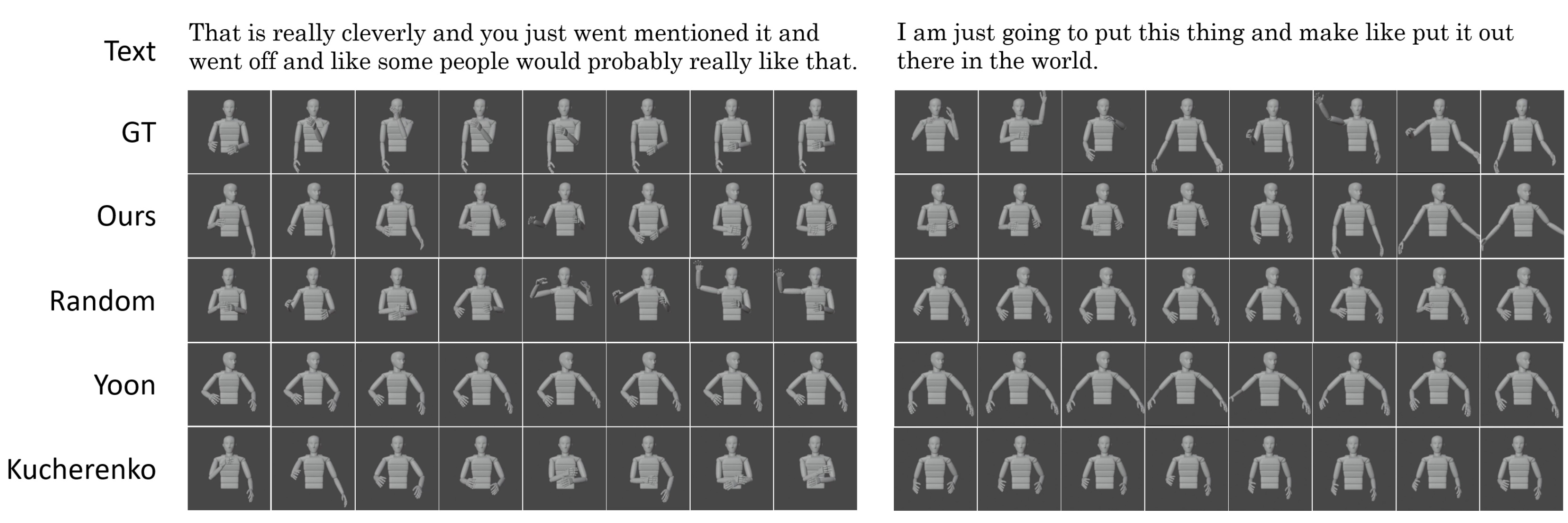
Resources
Publications
|
| Computer Vision and Graphics Laboratory |