Visual SLAM systems targeting static scenes have been developed with satisfactory accuracy and robustness.
Dynamic 3D object tracking has then become a significant capability in visual SLAM with the requirement of understanding dynamic surroundings in various scenarios including autonomous driving, augmented and virtual reality.
However, performing dynamic SLAM solely with monocular images remains a challenging problem due to the difficulty of associating dynamic features and estimating their positions.
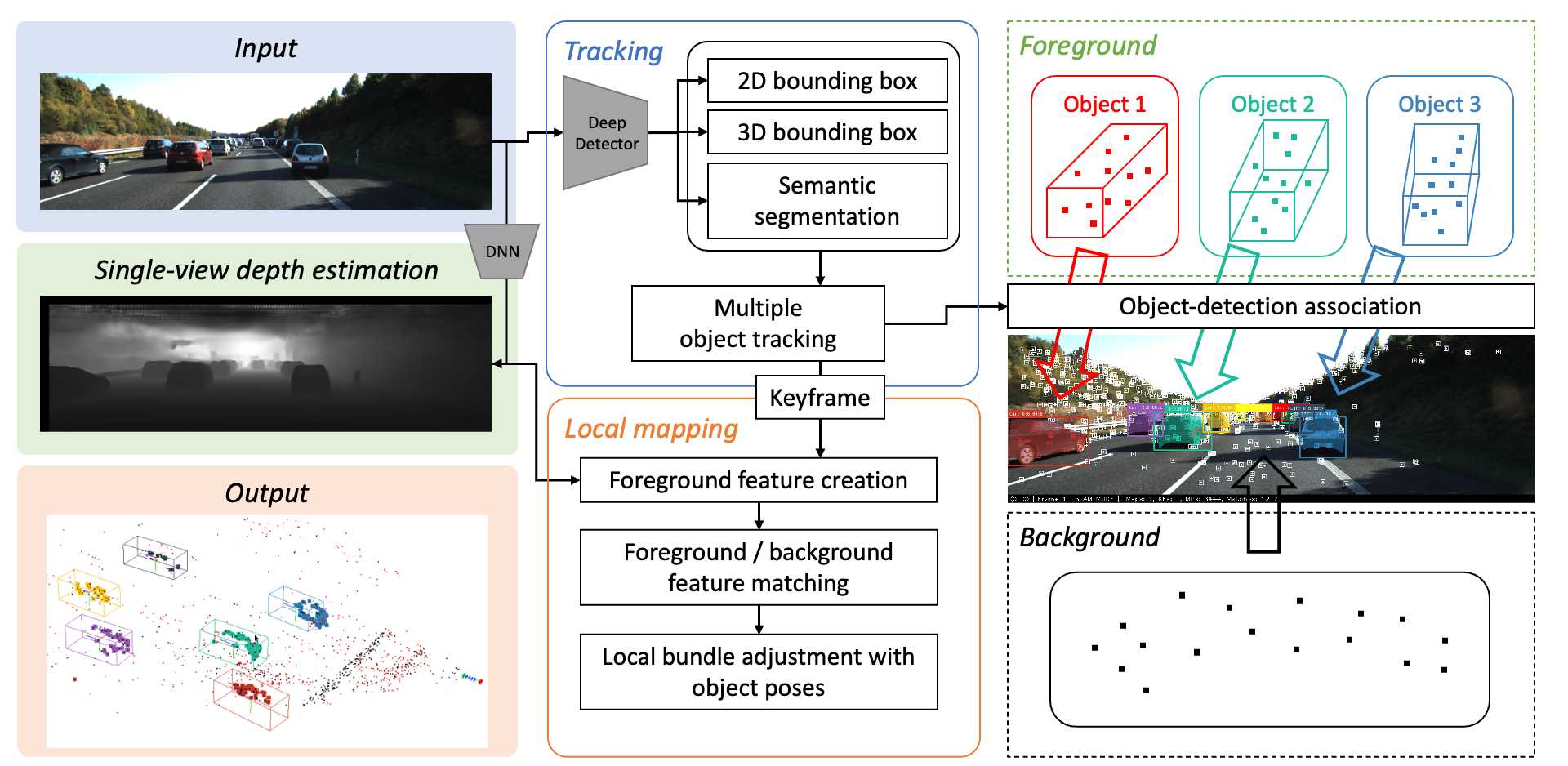
In this work, we present MOTSLAM, a dynamic visual SLAM system with the monocular configuration that tracks both poses and bounding boxes of dynamic objects.
MOTSLAM first performs multiple object tracking (MOT) with associated both 2D and 3D bounding box detection to create initial 3D objects.
Then, neural-network-based monocular depth estimation is applied to fetch the depth of dynamic features.
Finally, camera poses, object poses, and both static, as well as dynamic map points, are jointly optimized using a novel bundle adjustment.
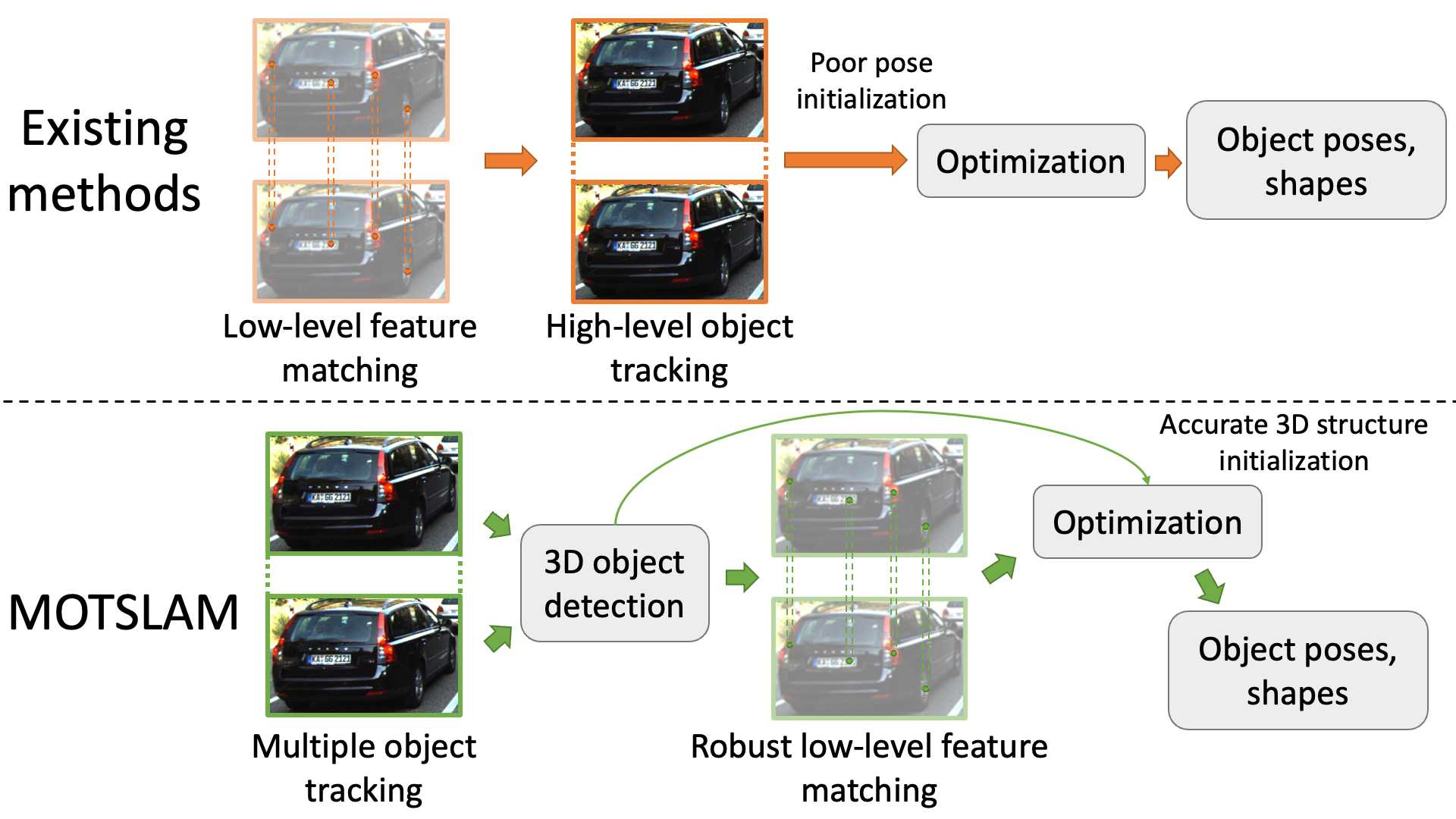
Existing works require low-level feature correspondences for high-level object association.
They usually adopt a linear motion model, which may be easily violated due to the various movement of objects in the real world.
More importantly, 3D reconstruction from sparse features without any prior usually generates unexpected shapes.
To address the above issues, we introduce multiple object tracking before dynamic feature tracking, which is our main contribution.
The MOT here reverts the order of low-level and high-level association.
At each new frame, objects are tracked by MOT before camera localization.
Therefore, for the rest part of this frame, we know relatively accurate poses and shapes of all current objects,
which provides strong motion prior to dynamic feature tracking and optimization.
In this way, we introduce single-view depth estimation to avoid the disadvantages of 2D-based feature matching for triangulation.
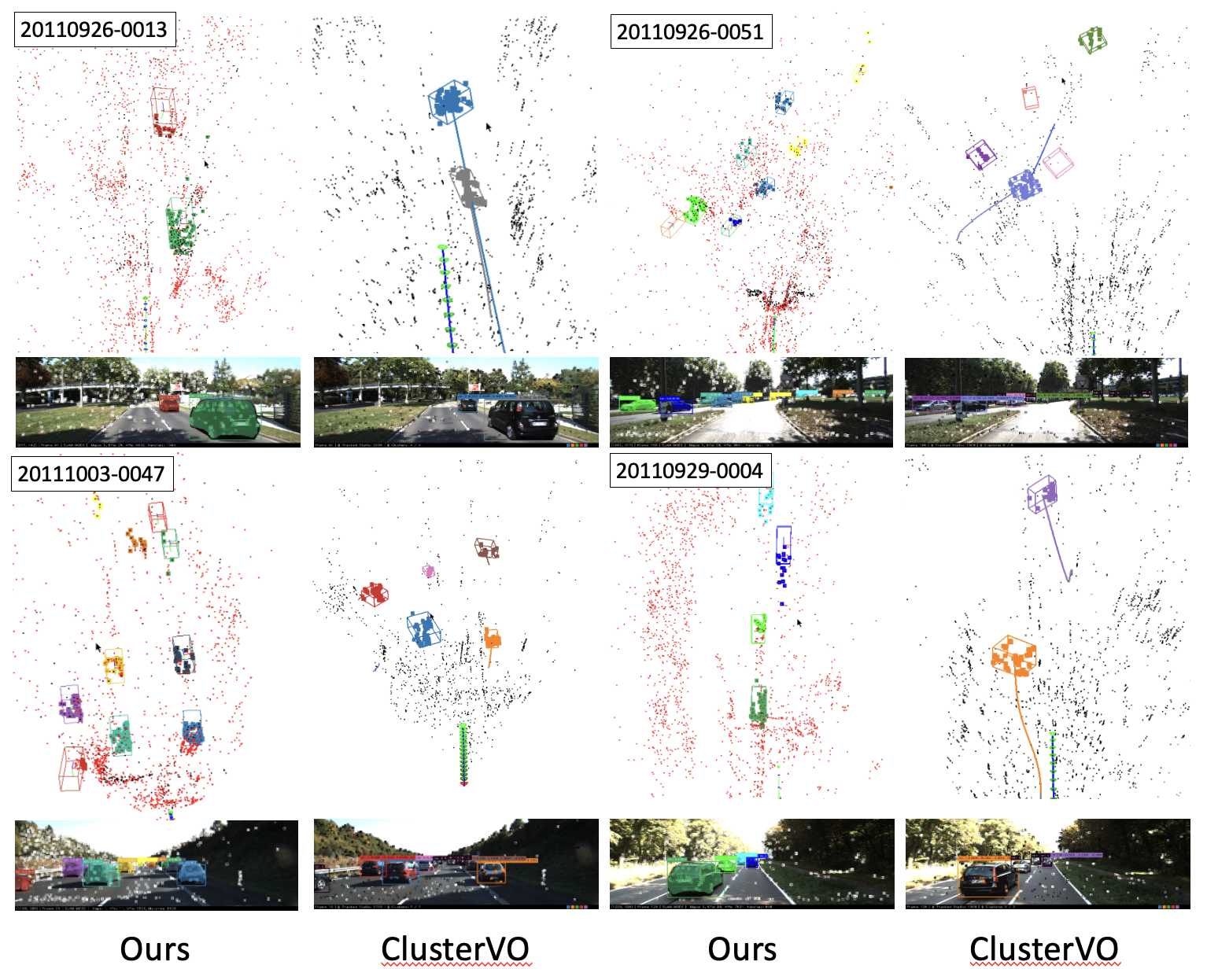
We evaluate our system on the KITTI dataset and focus on object tracking performance.
Our system outperforms existing state-of-the-art methods significantly on bounding box precision.
It can also track more objects and generate more regular vehicle shapes.
Publications
|