| Deep Gesture Generation for Social Robots Using Type-Specific Libraries |
In recent years, there has been a rapid development of media such as avatars and social robots. These are developed mainly for communication with humans, so one of the improvements to make them look more human-like is to make them perform more natural and appropriate gestures. Recent gesture generation systems tend to generate gestures by learning DNNs end-to-end from text, audio, and other modality. However, many previous studies simply combine speech and text features and input them to the network, making it difficult to generate gestures that match each modality. Therefore, we propose a method to generate gestures while explicitly taking into account the gesture type as text input.
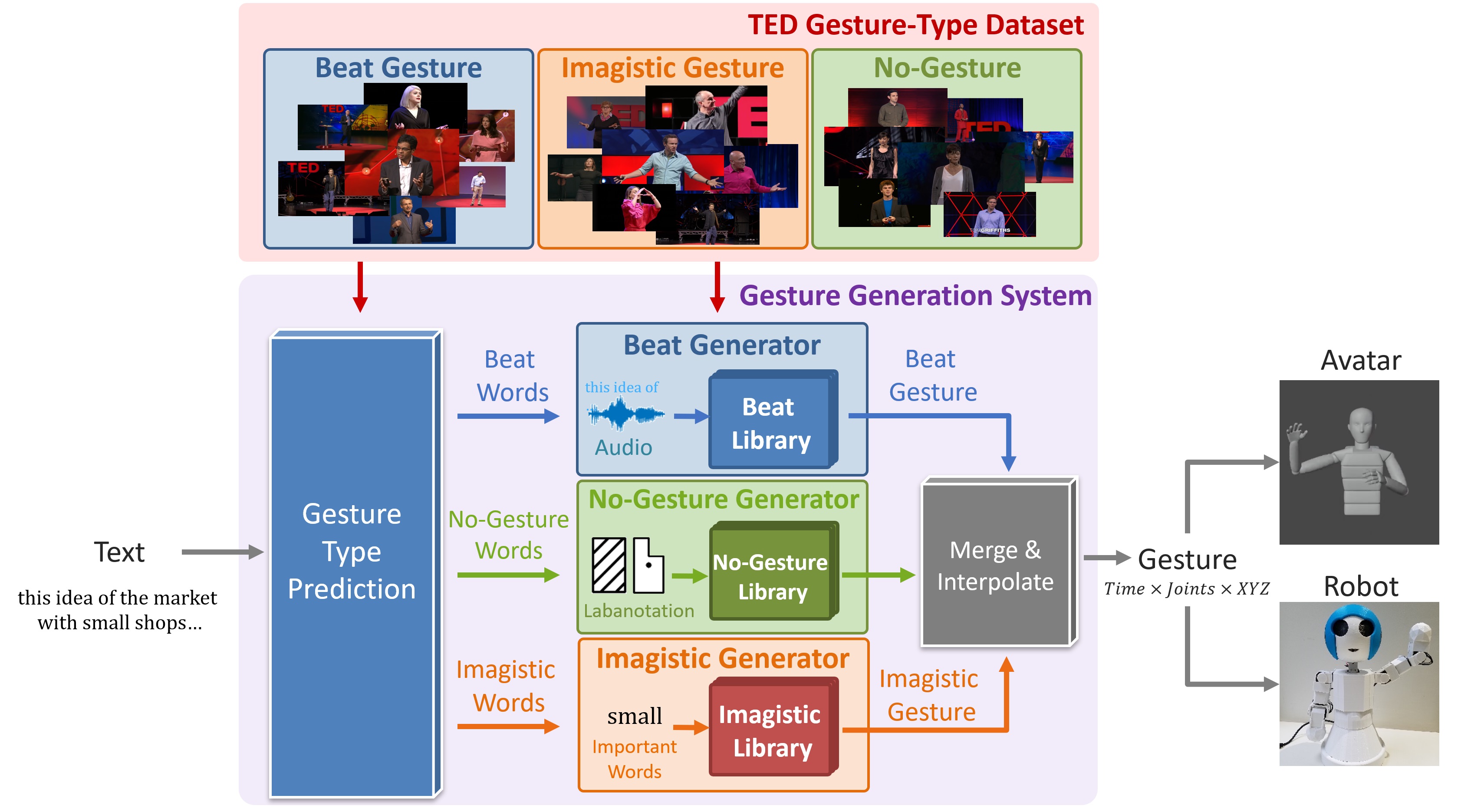
Each duration of the TED videos we deal with can be broadly classified into the following three types of movements (gesture types).
A gesture database annotated with gesture types is required when predicting gesture types from text and when building gesture libraries. Therefore, we used a crowdsourcing service to collect a new database as TED Gesture Type Dataset by segmenting TED videos by gesture and annotating them with gesture types. 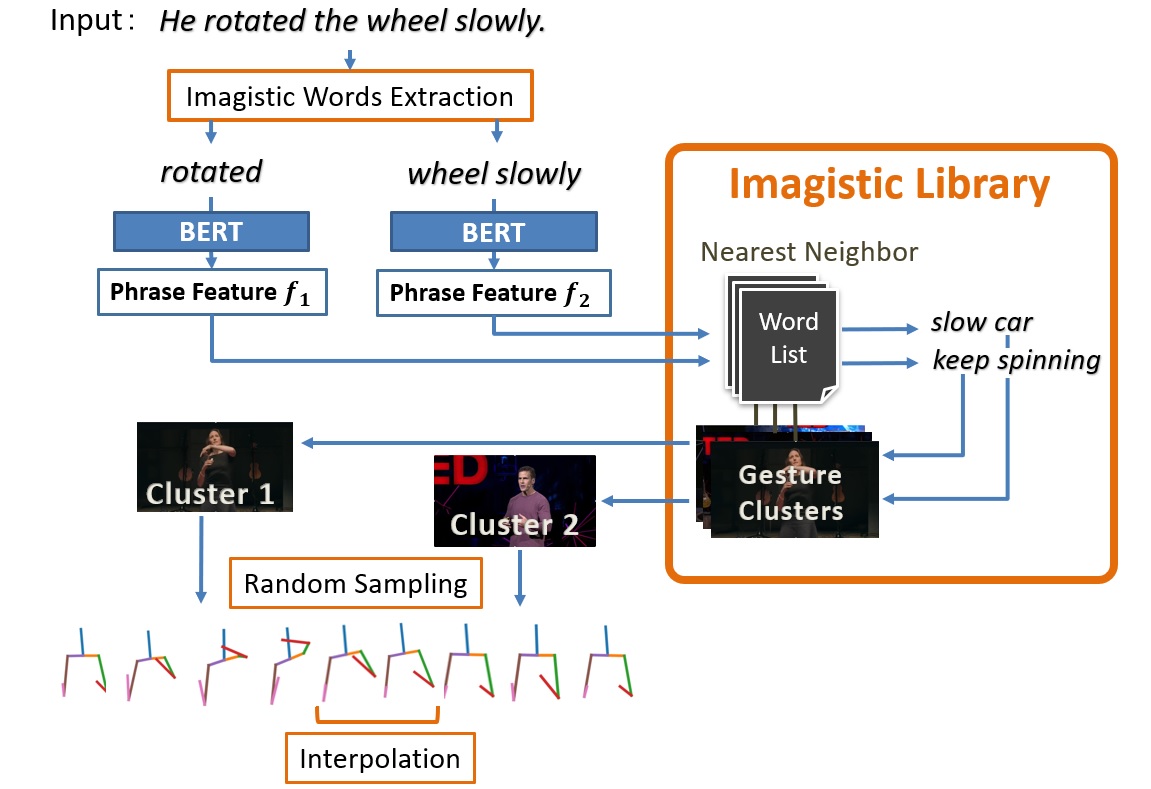
In the process of actually generating gestures from word sequences, for example, the Imagistic Generator first uses deep learning to select words in the input words that are likely to appear as Imagistic gestures. Then, each word is encoded using BERT and input into the gesture library, and the gesture cluster corresponding to the word with the closest meaning is retrieved from the library. A gesture is randomly selected from the retrieved gesture clusters and output. The following images are examples of actually generated gestures: the original gesture (GT), the gesture generated by our method (Ours), the gesture randomly referenced from the database (Random), and the gesture generated by the previous methods (Yoon , Kucherenko). 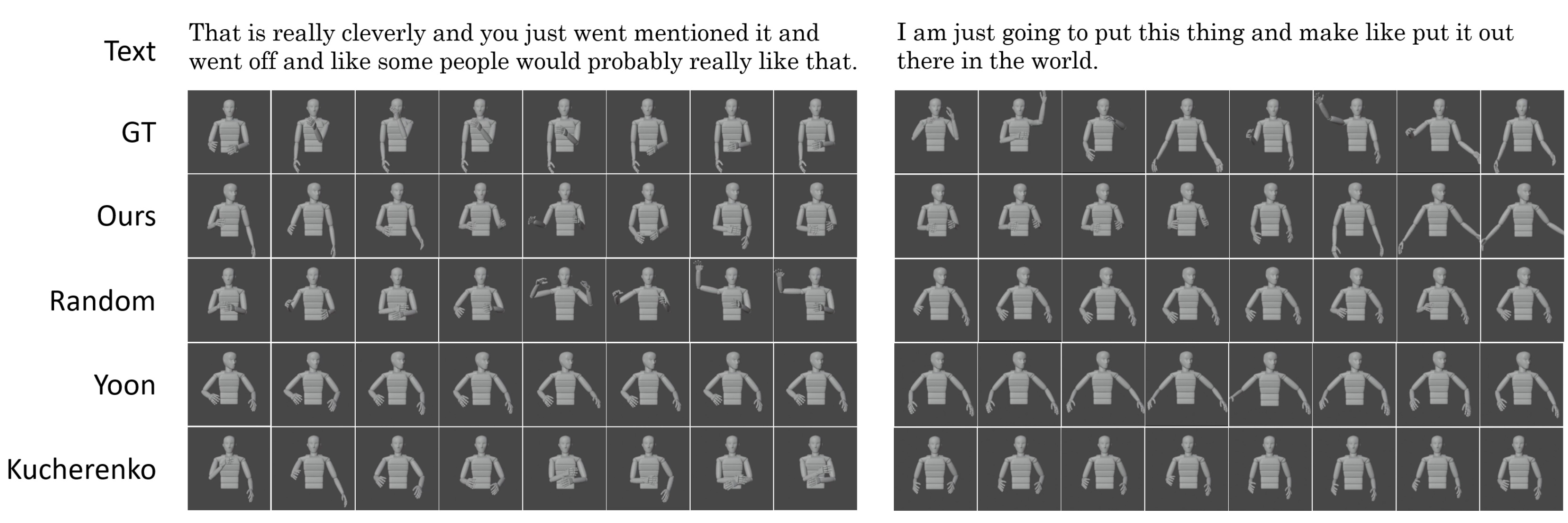
Resources
Publications
|
| Computer Vision and Graphics Laboratory |