|
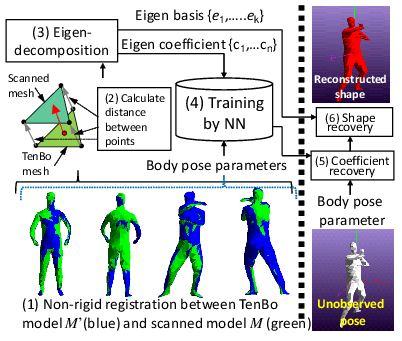
時系列で連続している3次元データからの人間の形状および動きの再構築は困難な問題です.近年ではオクルージョンで計測できない部分を補うために,人間の正確な全身スキャンに基づいて構成された統計的形状モデルを使用します.このような統計モデルは,タイトな衣類をきた人間の3次元スキャンで用いることができますが,ゆったりとした服を着た人間の衣類のしわなどの変形を表すことはできません.そこで我々は,人体のサーフェス形状をRGB-Dセンサなどで計測し,これとテンプレートによる基本3Dモデルとの差分を学習することで,任意の姿勢におけるサーフェス形状を再現することを目指します.
|
|
 input input |
 |
 vertex fitted model vertex fitted model |
 pose fitted model pose fitted model |
|
このようにRGB-Dセンサで計測された3次元点群から二つのモデルを作成し,これらの差分を取得します.
|
|  3 bases 3 bases |
 5 bases 5 bases |
 10 bases 10 bases |
 Cumulative contribution ratio Cumulative contribution ratio |
差分の計算は3次元点同士のベクトル差で求めます.3Dモデルの位置に依存しないようにそれぞれ体のパーツごとに計算します.
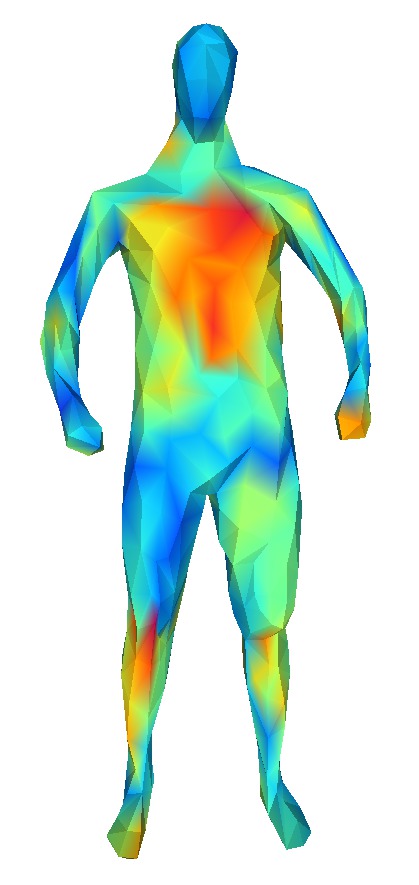
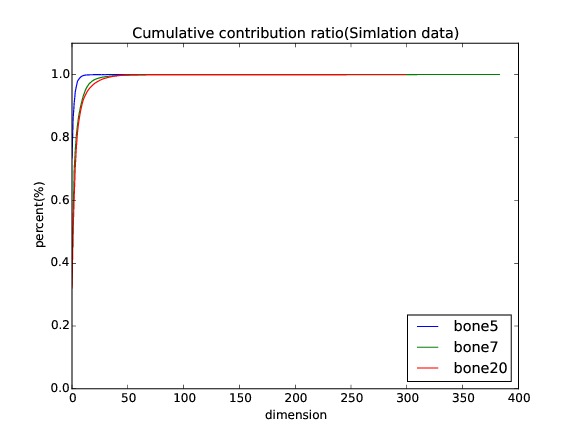
求めた差分で主成分分析を行い,次元圧縮をします.上の2つの図は主成分分析の結果を表しています.元データと主成分分析によって復元されたモデルとのRMSEを色で表しています.赤色ほどRMSEが大きく,青色ほど小さいです.
10主成分で元データの90%以上を表現することができます.主成分分析によって圧縮された行列を回帰します.
|
|
上記の動画は我々の手法によって復元した結果です.右の動画はシーケンス544フレーム中の0から6フレームを学習に使い,7から9フレーム目までを補間しました。
左の動画はシーケンス中の100フレームを補間しました.どちらもground truthとのRMSEを色で表しています.青色はground truthとの差が0,緑色は5cm,赤色は15cmを表しています。
Blue indicates ground truth and its difference 0, green 5 cm, red 15 cm.
|
Publications
|